Lock-free без сборки мусора
Это перевод статьи.
В нашей среде широко распространена мысль о том, что одним из преимуществ сборщика мусора является простота разработки высоко-производительных lock-free структур данных. Ручное управление памятью в них сделать не просто, а GC с лёгкостью решает эту проблему.
Этот пост покажет, что, используя Rust, можно построить API управления памятью для конкурентных структур данных, которое:
- Сделает возможным реализацию lock-free структуры данных, как это делает GC;
- Создаст статическую защиту от неправильного использования схемы управления памятью;
- Будет иметь сравнимые с GC накладные расходы (и более предсказуемые).
В тестах, которые я покажу ниже, Rust легко превосходит реализации lock-free очередей в Java, а саму реализацию на Rust легко написать.
Я реализовал схему управления памятью, основанную на эпохах («epoch-based memory reclamation») в новой библиотеке Crossbeam, которая на сегодняшний день готова к использованию с вашими структурами данных. В этом посте я расскажу о lock-free структурах данных, алгоритме эпох и внутреннем API Rust.
Тесты
Перед тем, как погрузиться в глубины спроектированного API и использованию эпох в управлении памятью, перейдём к главному: производительности.
Для сравнения накладных расходов моей реализации в Crossbeam с реализацией с полноценным GC, я для начала реализовал базовый алгоритм lock-free очереди (классическая очередь Michael-Scott) и создал точно такую же очередь в Scala. В общем случае языки на основе JVM прекрасно подходят для построения lock-free структур данных «с полноценным GC».
В дополнении к этим реализациям, я производил сравнения с:
-
Более эффективной «сегментированной» очередью, которая располагает элементы в нескольких слотах. Я написал эту очередь на Rust ещё на заре Crossbeam.
-
Однопоточной очередью на Rust, защищающуюся с помощью Mutex.
-
Реализацией очереди java.util.concurrent (ConcurrentLinkedQueue), которая представляет собой доработанный вариант очереди Michael-Scott.
Я тестировал очереди двумя способами:
Сценарий с множеством производителей и одним потребителем (A multi-producer, single-consumer, MPSC), в котором два потока неоднократно посылают сообщения, а один поток получает их в непрерывном цикле.
Сценарий с множеством производителей и множеством потребителей (A multi- producer, multi-consumer, MPMC), в котором два потока посылают сообщения и два потока принимают их в непрерывном цикле.
Тесты, подобные этим, довольно типичны для измерения масштабируемости lock-free структур данных в режиме «соперничества» — несколько потоков одновременно борются за конкурентное обновление. Необходимо тестировать множество вариантов использования очереди при построении реализации для production; здесь цель — это просто приблизительно оценить накладные расходы, добавляемые схемой управления памятью.
Для теста MPSC я также добавил сравнение с встроенным в Rust алгоритмом каналов, который как раз оптимизирован под этот вариант использования (и, следовательно, не поддерживает MPMC).
Использовалась машина — 4 ядра 2.6Ghz Intel Core i7 и 16GB RAM.
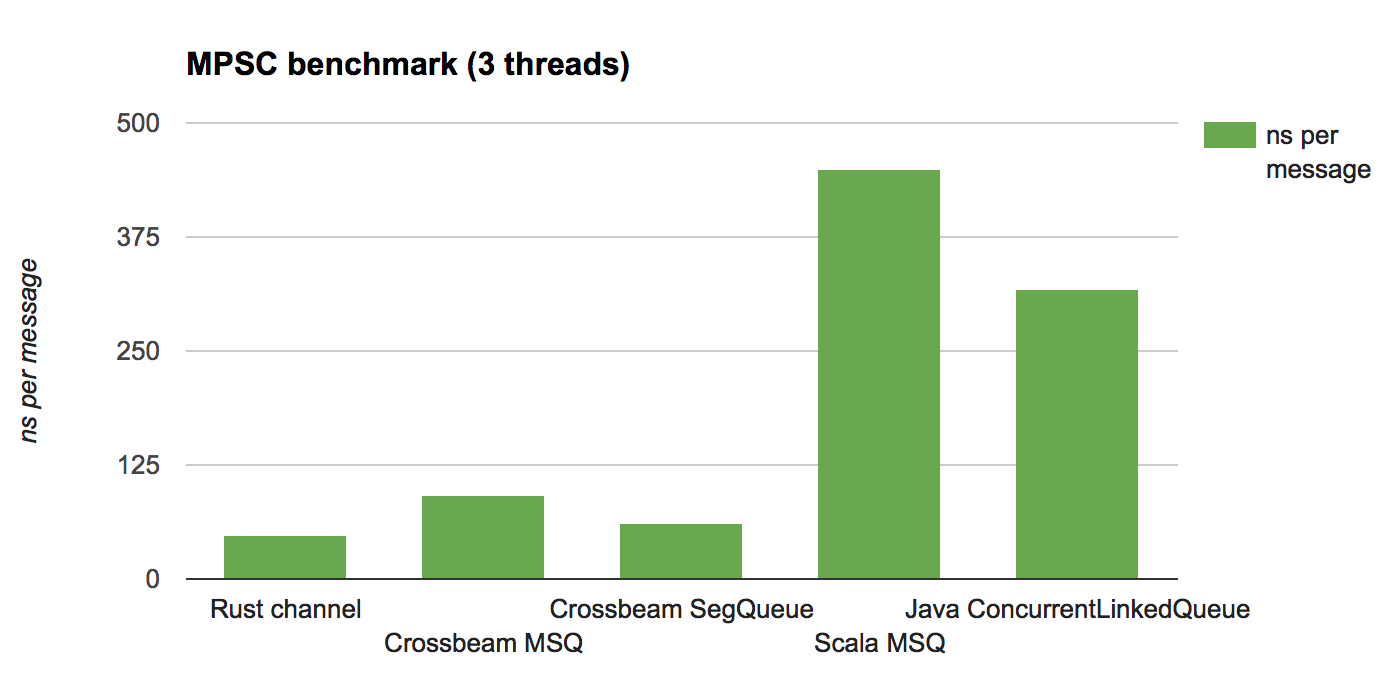
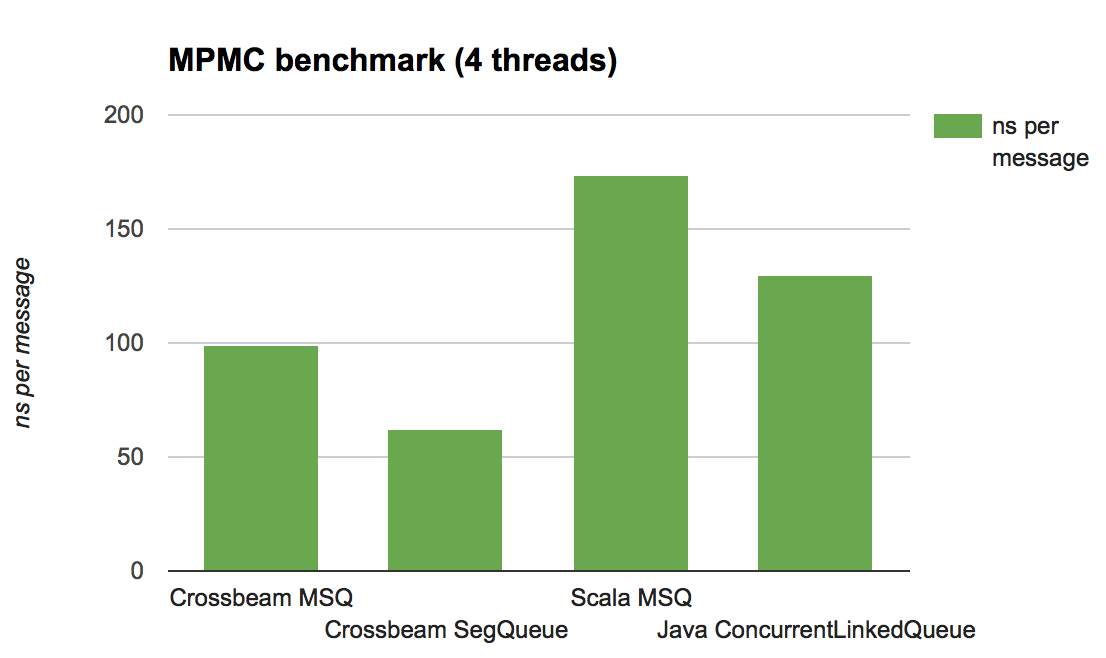
Вот результаты, приводящиеся в количестве наносекунд на сообщение (чем меньше, тем лучше):
Анализ
Главный вывод — это то, что реализация в Crossbeam — которую не дорабатывали под конкретные случаи — конкурентоспособна во всех случаях. Можно сделать лучше реализацию и на Rust и на JVM, используя более умные или специализированные очереди, но по крайней мере эти результаты показывают, что накладные расходы, добавляемые схемой управления памятью, основанную на эпохах, оправдывают себя.
Заметьте, что версии Java/Scala гораздо лучше ведут себя в тесте MPMC, чем в MPSC. Почему так?
Ответ прост: сборщик мусора. В тесте MPSC производители, как правило, обгоняют потребителя по времени, что означает, что количество данных в очередях медленно растёт. Что в свою очередь увеличивает цену каждой сборки мусора, заставляя сборщика проходить по увеличивающемуся живому набору данных.
В схеме эпох, наоборот, цена управления мусором относительно фиксирована: она пропорциональна количеству потоков, а не количеству живых данных. Из этого следует как лучшая, так и более постоянная/предсказуемая производительность.
Наконец, один вариант, который я не включил в график сравнений (потому что он сильно отстаёт от других), был с использованием Mutex во время извлечения данных из очереди, написанный на Rust. Для теста MPMC производительность была около 3040 нс/операция, что в 20 раз медленнее, чем реализация из Crossbeam. Это наглядная демонстрация того, почему важны lock-free структуры данных — начнём же погружаться в них.
Lock-free структуры данных
Если вы хотите использовать (и изменять) структуру данных из нескольких конкурирующих потоков, вам нужна синхронизация. Самое простое решение — это глобальный lock — в Rust можно обернуть внутреннюю структуру данных в Mutex и вызывать её хоть целый день.
Проблема в том, что такая «грубая» синхронизация означает, что несколько потоков постоянно должны координировать свой доступ к структуре данных, даже если они обращаются к непересекающимся её частям. Это также означает, что если поток пытается только прочесть данные, он должен выполнить запись, обновляя статус lock — и из-за того что lock — это глобальная точка связи, такие записи приводят к большому количеству трафика инвалидации кэша. Даже если вы используете несколько более «тонких» lock, появляются другие угрозы, такие как дедлок и инверсия приоритетов, а производительность все равно сильно падает.
Гораздо радикальной альтернативой являются lock-free структуры данных, которые используют атомарные операции для выполнения изменений напрямую в структуре данных без дальнейшей синхронизации. Зачастую они быстрее, лучше масштабируются, и надёжнее, чем lock-based алгоритмы.
Я не пытаюсь дать полный обзор lock-free программированию в этом посте, а главный посыл, который надо понимать, это то, что если у вас нет глобальной синхронизации, то очень сложно сказать, когда же можно освободить память. Множество опубликованных алгоритмов обычно подразумевают, что есть сборщик мусора или какой-то другой способ восстановления памяти. Поэтому, прежде чем отправиться по lock-free конкуренции в Rust, нужно рассказать про восстановление памяти — и именно об этом пойдёт речь в данном посте.
Стек Treiber’а
Для большей конкретики взглянем на «Hello world» в lock-free структурах данных: на стек Treiber’а. Стек представляет собой односвязный список, а все изменения касаются указателя на head:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #![feature(box_raw)] use std::ptr::{self, null_mut}; use std::sync::atomic::AtomicPtr; use std::sync::atomic::Ordering::{Relaxed, Release, Acquire}; pub struct Stack<T> { head: AtomicPtr<Node<T>>, } struct Node<T> { data: T, next: *mut Node<T>, } impl<T> Stack<T> { pub fn new() -> Stack<T> { Stack { head: AtomicPtr::new(null_mut()), } } } |
Самое простое — начать с метода pop. Для этого заходим в цикл, берём слепок head и выполняем compare-and-swap, заменяющий слепок на указатель на следующий элемент:
1 2 3 4 | Заметьте, что compare_and_swap автоматически меняет значение AtomicPtr со старого значения на новое, если старое значение совпадает. В этом посте можете также спокойно пропускать метки Acquire, Release и Relaxed, если они вам не знакомы. |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | impl<T> Stack<T> { pub fn pop(&self) -> Option<T> { loop { // делаем слепок let head = self.head.load(Acquire); // проверяем, что стек не пустой if head == null_mut() { return None } else { let next = unsafe { (*head).next }; // если слепок все ещё хороший, заменяем `head` на `next` if self.head.compare_and_swap(head, next, Release) == head { // вытаскиваем данные узла, больше ни с кем не связанного // **ВНИМАНИЕ**: утечка узла! return Some(unsafe { ptr::read(&(*head).data) }) } } } } } |
Функция ptr: read — это способ передать владение данными в Rust без статического или динамического отслеживания этого. Здесь мы используем атомарность compare_and_swap, чтобы гарантировать, что только один поток вызовет ptr: read — а, как мы увидим, эта реализация никогда не освобождает узлы из памяти, поэтому деструктор данных никогда не вызывается. Эти два факта вместе делают использование ptr: read безопасным.
Метод push похож на pop:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | impl<T> Stack<T> { pub fn push(&self, t: T) { // размещаем в памяти узел, и сразу же превращаем его в *mut pointer let n = Box::into_raw(Box::new(Node { data: t, next: null_mut(), })); loop { // делаем слепок текущей head let head = self.head.load(Relaxed); // обновляем указатель `next` на слепок unsafe { (*n).next = head; } // если слепок все ещё хороший, связываем новый узел if self.head.compare_and_swap(head, n, Release) == head { break } } } } |
Проблема
Если бы мы написали этот код в языке с GC, то на этом бы все и закончилось. Но, как написано сейчас в Rust, память будет утекать. В частности, реализация pop не пытается освободить память из-под указателя в узле после его удаления из стека.
Что пойдёт не так, если мы добавим освобождение памяти?
1 2 3 4 5 6 7 | // вытаскиваем данные узла, больше ни с кем не связанного let ret = Some(unsafe { ptr::read(&(*head).data) }); // освобождаем узел mem::drop(Box::from_raw(head)); return ret |
Проблема в том, что другие потоки могли тоже в этот же момент вызывать pop. У них может быть слепок текущей head; ничего не ограничивает их от чтения (*head).next у их слепка сразу после того, как мы освободили узел, на который они ссылаются — в самом явном виде баг использование-после-освобождения!
Вот в этом то и суть вопроса. Мы хотим использовать lock-free алгоритмы, но многое в них приведёт к поведению аналогичному поведению стека выше, оставляя нас в полном неведении, когда же можно безопасно удалить узел. И что дальше?
Схема управления памятью, основанная на эпохах
Есть несколько не основанных на GC способах управления памятью для lock-free кода, но все они сводятся к одним и тем же наблюдениям:
-
Здесь есть два варианта достать данные — из самой структуры данных и из слепков в потоках, обращающихся к структуре. Прежде, чем мы удалим какой-либо узел, мы должны быть уверены, что его нельзя достать ни одним из этих способов.
-
Когда узел не связан со структурой данных, нельзя будет создать слепок, который может обратиться к нему.
Одной из самых элегантных и многообещающих является схема, основанная на эпохах Keir Fraser’а, которая была описана в свободных терминах в его докторской диссертации.
Основной идеей является спрятать подальше несвязанные узлы от структуры данных (первый вариант доступа к данным) до тех пор пока их можно будет безопасно удалить. Прежде, чем мы можем удалить спрятанный узел, нам надо знать, что все потоки обращавшиеся к структуре данных в это время уже закончили свою работу. Наблюдение 2 выше подразумевает, что не осталось слепков спрятанного узла (из-за того, что новые слепки не могли создастся в это время). Самой сложной частью является сделать это все без синхронизации. Иначе мы потеряем выигрыш, который и должна приносить нам свобода от блокировок в первую очередь!
Схема эпох работает, используя следующее:
1.Глобальный счётчик эпохи (принимающий значения 0, 1 или 2); 2.Глобальный список мусора для каждой эпохи; 3.Флаг «активности» для каждого потока; 4.Счётчик эпохи для каждого потока.
Эпохи нужны, чтобы понять, когда мусор можно безопасно освободить из памяти, потому что он не доступен ни одному из потоков. В отличие от традиционного GC это не требует прохода по живым данным; это сугубо проверка счётчиков эпох.
Если поток хочет выполнить какую-нибудь операцию со структурой данных, он сначала поднимает свой флаг «активности», и затем обновляет свою локальную эпоху, чтобы она совпадала с глобальной. Если поток удаляет узел из структуры данных, он добавляет этот узел в список мусор текущей глобальной эпохи. (Внимание: очень важно, чтобы мусор шёл в текущей глобальной эпохе, а не в предыдущем локальном слепке.) После окончания операции поток снимает флаг «активности».
Для того, чтобы попытаться собрать мусор (что можно сделать в любой момент), поток проходится по флагам всех участвующих потоков и проверяет все ли активные потоки находятся в текущей эпохе. Если это так, он может попытаться увеличить глобальную эпоху (по модулю 3). Если увеличение проходит успешно, мусор из двух эпох назад может быть освобождён из памяти.
Зачем нам три эпохи? Потому что «сборка мусора» происходит параллельно, а потоки могут находится в одной из двух эпох в любой момент (ещё в «старой» или уже в «новой»). Но из-за того, что мы проверяем, что все активные потоки находятся в старой эпохе перед её увеличением, мы гарантируем, что ни один из потоков не находится в третьей эпохе (две эпохи назад).
Эта схема спроектирована так, что большинство времени потоки имеют дело с данными, которые уже в кэше или (обычно) локальны для потоков. Только выполнение «GC» включает в себя изменение глобальной эпохи или чтение эпох других потоков. Подход управления памятью с помощью эпох не зависит от алгоритма структуры данных, прост в использовании, а его производительность конкурентоспособна с другими подходами.
Оказалось, что он прекрасно ложится на систему владений Rust.
Rust API
Мы хотим, чтобы Rust API отражало базовые принципы управления памятью, основанной на эпохах:
-
При работе со структурой общих данных, поток должен быть всегда в «активном» состоянии.
-
Если поток активен, все прочтённые данные из структуры остаются размещёнными в памяти до тех пор пока поток не станет неактивным.
Мы усилим систему владений Rust — в частности, управление ресурсами на основе владения (RAII) — чтобы она ловила эти ограничения напрямую в сигнатурах типов API эпох. Это в свою очередь докажет, что мы используем управление эпохами правильно.
Guard
Для работы с lock-free структурой данных, для начала надо получить обладаемое охранное значение, говорящее о том, что ваш поток активен:
1 2 | pub struct Guard { ... } pub fn pin() -> Guard; |
Функция pin даёт потоку флаг активности, загружает глобальную эпоху, и может попытаться выполнить GC (объясняется чуть позже в посте). Деструктор Guard, с другой стороны, выходит из управления эпохами помечая поток флагом неактивности.
В связи с тем, что Guard представляет собой «активность», заимствованный & ’a Guard гарантирует, что поток активен на время жизни ‘a — именно то, что нам нужно, чтобы ограничить время жизни слепка, взятого в lock-free алгоритме.
Для использования Guard Crossbeam предоставляет набор из трёх типов указателей, предназначенных для совместной работы:
-
Owned<T>, сродниBox<T>, который указывает на данные с одним уникальным владельцем, которые ещё не были добавлены в конкурентную структуру данных. -
Shared<'a, T>, сродни & ’a T, который указывает на разделяемые данные, которые могут или не могут быть доступны из структуры данных, но он гарантирует, что они не будут освобождены из памяти в течение времени жизни ‘a. -
Atomic<T>, сродни std: sync: atomic: AtomicPtr, который предоставляет атомарное обновление указателя, используя типы Owned и Shared, и связывает их с Guard.
Рассмотрим каждый из них.
Указатели Owned и Shared
Указатель Owned обладает похожим на Box интерфейсом:
1 2 3 4 5 6 7 8 9 10 11 | pub struct Owned<T> { ... } impl<T> Owned<T> { pub fn new(t: T) -> Owned<T>; } impl<T> Deref for Owned<T> { type Target = T; ... } impl<T> DerefMut for Owned<T> { ... } |
Указатель Shared<'a, T> похож на & ’a T — он реализует Copy — но разыменовывается
в & ’a T. Это такой хитрый способ передать, что время жизни указателя, который он
предоставляет, на самом деле равно ‘a.
1 2 3 4 5 6 7 8 9 | pub struct Shared<'a, T: 'a> { ... } impl<'a, T> Copy for Shared<'a, T> { ... } impl<'a, T> Clone for Shared<'a, T> { ... } impl<'a, T> Deref for Shared<'a, T> { type Target = &'a T; ... } |
В отличие от Owned, указатель Shared нельзя создать напрямую. Вместо этого, указатели Shared получаются посредством чтения из Atomic, что мы увидим далее.
Atomic
Сердцем библиотеки является Atomic, который предоставляет атомарный доступ к указателю (может быть null) и связывает между собой другие типы в библиотеке:
1 2 3 4 5 6 | pub struct Atomic<T> { ... } impl<T> Atomic<T> { /// создаёт новый, нулевой атомарный указатель. pub fn null() -> Atomic<T>; } |
Рассмотрим по очереди каждую операцию, потому что для каждой из них есть своя хитрость.
Загрузка
Во-первых, загрузка из Atomic:
1 2 3 | impl<T> Atomic<T> { pub fn load<'a>(&self, ord: Ordering, _: &'a Guard) -> Option<Shared<'a, T>>; } |
Для выполнения загрузки мы должны передать заимствованный Guard. Как объяснялось выше, это способ гарантировать, что поток будет активен во время жизни ‘a. Возвращается опциональный Shared указатель (None, если Atomic сейчас равен null), с временем жизни, привязанным к охранному значению.
Интересно сравнить его с интерфейсом AtomicPtr из стандартной библиотеки, в которой загрузка возвращает *mut T. Из-за использования эпох мы можем гарантировать безопасное разыменование указателя во время жизни ‘a, в то время как с AtomicPtr ничего такого нет.
Сохранение
Сохранение немного посложнее, потому что в деле есть несколько типов указателей.
Если мы просто хотим сохранить Owned указатель или нулевое значение, нам не нужно, чтобы поток был активным. Мы просто передаём владение в структуру данных, и нам не нужно никаких гарантий времени жизни указателей:
1 2 3 | impl<T> Atomic<T> { pub fn store(&self, val: Option<Owned<T>>, ord: Ordering); } |
Хотя иногда мы хотим передать владение структуре данных и немедленно получить указатель на переданные данные — например, потому что нам надо добавить дополнительные связи в этот же узел в структуре данных. В этом случае нам надо привязать время жизни к охранному значению:
1 2 3 4 5 6 7 | impl<T> Atomic<T> { pub fn store_and_ref<'a>(&self, val: Owned<T>, ord: Ordering, _: &'a Guard) -> Shared<'a, T>; } |
Заметьте, что представление во время исполнения у val и возвращаемого значения абсолютно одинаковое — мы передаём указатель внутрь и получаем тот же указатель снаружи. Но ситуация с владениями с точки зрения Rust на этом шаге кардинально меняется.
Наконец, мы можем сохранить указатель в структуре данных:
1 2 3 | impl<T> Atomic<T> { pub fn store_shared(&self, val: Option<Shared<T>>, ord: Ordering); } |
Защитник здесь не нужен, потому что мы не узнаем никакой новой информации о времени жизни указателя.
CAS
Следующее, что у нас есть — это семейство операций compare-and-set. Самый простой случай — это заменить Shared указатель на новый Owned указатель:
1 2 3 4 5 6 7 | impl<T> Atomic<T> { pub fn cas(&self, old: Option<Shared<T>>, new: Option<Owned<T>>, ord: Ordering) -> Result<(), Option<Owned<T>>>; } |
Также как и с сохранением, этой операции не нужно охранное значение; оно не добавит никакой новой информации о времени жизни. Result показывает удачен ли CAS; если нет, то владение новым указателем возвращается тому, кто вызвал эту функцию.
Дальше у нас есть аналог store_and_ref:
1 2 3 4 5 6 7 | impl<T> Atomic<T> { pub fn cas_and_ref<'a>(&self, old: Option<Shared<T>>, new: Owned<T>, ord: Ordering, _: &'a Guard) -> Result<Shared<'a, T>, Owned<T>>; |
В этом случае, при удачном CAS мы получим Shared указатель на вставленные нами данные.
И последнее, мы можем заменить один Shared указатель другим:
1 2 3 4 5 6 7 | impl<T> Atomic<T> { pub fn cas_shared(&self, old: Option<Shared<T>>, new: Option<Shared<T>>, ord: Ordering) -> bool; } |
Возвращаемое булево значение равно true когда CAS успешен.
Освобождение памяти
Конечно, все перечисленные механизмы служат одной цели: по-настоящему освободить память, которая больше не достижима. Когда у узла разорвали связь со структурой данных, поток, который отделил его, может проинформировать своего Guard, что память должна быть очищена:
1 2 3 | impl Guard { pub unsafe fn unlinked<T>(&self, val: Shared<T>); } |
Эта операция добавляет Shared указатель в соответствующий список мусора, позволяя ей быть очищенной две эпохи спустя.
Операция небезопасна, потому что она подразумевает, что:
- Shared указатель недоступен из структуры данных,
- ни один другой поток не вызовет отделение этого узла.
Это важно, хотя, другие потоки могут продолжить ссылаться на этот Shared указатель; система эпох гарантирует, что ни один из потоков не будет ссылаться на узел после его действительного освобождения из памяти.
Здесь нет конкретной связи между временем жизни Shared указателя и Guard; если у нас есть достижимый Shared указатель, то мы знаем, что охранное значение, из которого он пришёл, все ещё активен.
Стек Treiber’а с эпохами
Без дальнейших пояснений, вот код стека Treiber’а, использующий API эпох Crossbeam:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | use std::sync::atomic::Ordering::{Acquire, Release, Relaxed}; use std::ptr; use crossbeam::mem::epoch::{self, Atomic, Owned}; pub struct TreiberStack<T> { head: Atomic<Node<T>>, } struct Node<T> { data: T, next: Atomic<Node<T>>, } impl<T> TreiberStack<T> { pub fn new() -> TreiberStack<T> { TreiberStack { head: Atomic::new() } } pub fn push(&self, t: T) { // размещение узла через Owned let mut n = Owned::new(Node { data: t, next: Atomic::new(), }); // ставим флаг активности let guard = epoch::pin(); loop { // делаем слепок текущей головы let head = self.head.load(Relaxed, &guard); // обновляем указатель `next` на слепок n.next.store_shared(head, Relaxed); // если слепок ещё хороший, связываем новый узел match self.head.cas_and_ref(head, n, Release, &guard) { Ok(_) => return, Err(owned) => n = owned, } } } pub fn pop(&self) -> Option<T> { // ставим флаг активности let guard = epoch::pin(); loop { // делаем слепок текущей головы match self.head.load(Acquire, &guard) { // если стек непустой Some(head) => { // читаем через слепок, *безопасно*! let next = head.next.load(Relaxed, &guard); // если слепок ещё хороший, обновляем из `head` в `next` if self.head.cas_shared(Some(head), next, Release) { unsafe { // помечаем узел как несвязанный guard.unlinked(head); // вытаскиваем данные узла, больше ни с чем не // связанного return Some(ptr::read(&(*head).data)) } } } // стек пуст None => return None } } } } |
Несколько замечаний:
Основная логика алгоритма такая же как у версии с GC, за исключением того что мы явно помечаем вытаскиваемый узел как «несвязанный». В общем случае можно взять «с полки» любой lock-free алгоритм (который подразумевает наличие GC) и закодировать его показанным способом с помощью Crossbeam.
После того как мы сделали слепок, мы можем разыменовать его, не используя unsafe, потому что охранное значение гарантирует его живучесть в этот момент.
Использование ptr: read здесь оправдано использованием нами compare-and-swap для того чтобы гарантировать, что только один поток вызывает его, и тем фактом, что схема управления памятью на эпохах не вызывает деструкторы, а просто освобождает память.
Последнее замечание об освобождении памяти требует более развёрнутого комментария, поэтому рассмотрим описание API через разговор о сборке мусора.
Управление мусором
Дизайн Crossbeam использует управление эпохами как сервис, разделяемый всеми структурами данных: есть одна статическая переменная для глобального состояния эпохи, и у каждого потока своя локальная переменная состояния. Это делает API эпох очень простым в использовании, из-за того что нет никаких подстроек под данные структуры. Это также означает, что используемое пространство (гораздо тривиальней) связано с количеством потоков, использующих эпохи, а не со структурой данных.
Единственным отличием реализации в Crossbeam от существующей литературы по эпохам является то, что каждый поток хранит свой локальный список мусора. Связано это с тем, что, когда поток помечает узел как «несвязанный», этот узел добавляется в локальные для потока данные, а не в глобальный список мусора (что потребовало бы дополнительной синхронизации).
Каждый раз, когда вы вызываете epoch: pin(), текущий поток проверяет превышает ли локальный мусор порог сборки, и если так, он попробует освободить место. Аналогично, когда вы вызываете epoch: pin(), если глобальная эпоха отличается от предыдущего слепка, текущий поток может собрать какой-от её мусор. Кроме того, что удаётся избежать глобальной синхронизации списков мусора, эта новая схема распределяет работу по фактическому освобождению памяти по всем потокам, обращающимся к структуре.
Из-за того, что GC может производиться только, когда активные потоки находятся в текущей эпохе, не всегда можно собрать мусор. Но на практике, мусор в потоке редко превышает пороговое значение.
Хотя есть одна уловка: из-за того, что GC может закончится неудачей, если поток завершается, нужно что-то сделать с мусором этого потока. Поэтому в реализации Crossbeam есть глобальный список мусора, который используется как место последней надежды для выкидывания мусора, когда поток завершается. Эти глобальные списки мусора собираются потоком, который удачно увеличит глобальную эпоху.
Наконец, что это означает, «собрать» мусор? Как показано выше, библиотека только освобождает память; она не вызывает деструкторы.
Принципиально то, что фреймворк разбивает удаление объекта на две части: удаление/перемещение внутренних данных, и освобождение из памяти объекта, содержащего их. Первое должно произойти в то же время, когда вызывается разрыв связи — это время, когда есть уникальный поток, владеющий объектом во всех смыслах этого слова кроме возможности освободить память из-под него. Второе происходит в какой-то неизвестный момент времени, когда известно, что объект ни с чем больше не связан. Это накладывает обязательства на пользователя: доступ посредством слепка должен осуществляться только по чтению данных, которые правильны до освобождения памяти из-под объекта. Но обычно это единственный вариант для lock-free структур данных, в которых есть чёткая граница между данными относящимися к контейнерам (т.е., поля Atomic), и действительным содержимым данных (поля данных в Node).
Разделение удаления объекта таким способом означает, что деструкторы запускаются синхронно, в предсказуемое время, обходя одну из болевых точек GC, что позволяет использовать фреймворк для не-‘static (и не-Send) данных.
Дорога дальше
Crossbeam все ещё находится в младенчестве. Работа ведётся в направлении закладки фундамента в исследование широкого спектра lock-free структур данных в Rust, и я надеюсь, что Crossbeam будет играть похожую на java.util.concurrent роль в Rust — включать в себя lock-free hashmap, work-stealing очереди, и механизм легковесных заданий. Если вам интересна эта работа, мне бы очень не помешала ваша помощь!